
The Bash Parser
This page informally describes parsing, expansion, and argument handling, but fuzzes some important distinctions that depend upon the type of command being handled. See Bash grammar and Parsing and execution on bash-hackers for a better look at this. It is important that you have a good understanding of how Bash reads your commands in and parses them into executable code, but even more important to understand the grammar of the language than implementation-specific parser details.
Parsing
There are several stages of parsing which occur in multiple passes: on the level of entire script files; within individual commands; and line-by-line. Code undergoes several intermediary internal representations throughout the evaluation process, some of which can't be analyzed through Bash's debugging facilities.
During Bash's initial intake of code -- as it reads source files or interactive input -- commands are parsed both line-by-line and command-by-command. Certain aspects of parsing are tied closely with lines. HereDocument parsing, some error handling behaviours, and some details of metacharacter parsing (e.g. extglobs) are tied to newlines. The extent to which Bash deals in "lines" is unclear and there is considerable variation across different shells. For example, some shells will accept !; cmd or ! !; cmd, whereas Bash requires a real newline and can't handle a semicolon in this case. Still other shells can't handle either type of null pipeline even with a newline.
In other respects, Bash parses commands in chunks whose scope encompasses roughly that of the current compound command. Most will notice this when they accidentally forget a closing fi, or semicolon before a closing curly-brace command group.
Aside from syntax errors, most of the time you don't need to think about this part of parsing. It's the actual evaluation of the commands (and intermediary parsing steps that happen at that time) that matters. Nevertheless, you may run across these considerations in some advanced cases when writing portability wrappers involving code that a particular shell implementation chokes on, or when Bash handles errors that are sensitive to newlines. Much of this behaviour is unspecified, some differs between Bash POSIX and normal mode, and a few are likely bugs or just coincidental behaviour.
Command splitting
Step 1: Read data to execute.
Data is parsed as described above with various details differing depending upon interactive mode, POSIX mode, and certain shell options. Lines that end in the middle of a context that allows continuation to the next line are considered as a whole. An incomplete list of examples: compound array assignments; lines ending in a pipeline operator, list operator other than ; or &; lines ending within a quoted context without a closing quote, in the middle of a compound command, an unclosed command substitution, or a simple command ending in a backslash character.
Step Input:
echo "What's your name?"
read name; echo "$name"
Step Output:
echo "What's your name?"
and
read name; echo "$name"
Step 2: Process quotes.
- ( Note: the next three steps are somewhat interconnected and dependent on one another. Describing them separately is an approximation. )
Roughly, once Bash has read in your line of data, it looks through in search of quotes. Bash does its best during this phase to make exceptions for brace expansion and other factors that disrupt simple quote nesting rules like command substitutions and some nested parameter expansions.
Aside from that, the first "bare" quote it finds triggers a quoted state for all characters that follow up until the next quote of the same type. Note that bash doesn't actually process the contents of the quoted regions at this stage except to the extent necessary to determine later command splitting steps.
If the quoted state was triggered by a double quote ("..."), all characters except for $, " and \ lose any special meaning they might have. That includes single quotes, spaces and newlines, etc. If the quoted state was triggered by a single quote ('...'), all characters except for ' lose their special meaning. Yes, also $ and \. If the quoted state was triggered by $'...', then all characters except for \ and ' lose their special meaning. Therefore, the following command will produce literal output:$ echo 'Back\Slash $dollar "Quote"' Back\Slash $dollar "Quote"
The fact that the backslash loses its ability to cancel out the meaning of the next character means that this will not work:$ echo 'Don\'t do this' >Bash will ask you for the next line of input because unlike what we thought we did, the second quote, the one we tried to escape with the backslash, actually closed our quoted state meaning the t do this was not quoted. The last quote on the line then opened our quoted state again, and bash asks for more input until it is closed again (it tries to finish step 1: it reads data until it finds an unescaped newline. The opened single quote state is escaping our newline). Now that Bash knows which of the characters in the line of data are escaped (stripped of their ability to mean anything special to Bash) and which are not, Bash removes the quotes that were used to determine this from the data and proceeds to the next step.
Step Input:
echo "What's your name?"
Step Output:
echo What's your name?
(Note: Every character originally between the double quotes has been marked as escaped. I will mark escaped characters in these examples by making them italic.)
Step 3: Split the read data into commands.
Our line is now split up into separate commands using ;, &, ||, &&, and characters defined as metacharacters such as ( and ) as command separators (Bash doesn't always do this correctly). Remember from the previous step that any ; characters that were quoted or escaped do not have their special meaning anymore and will not be used for command splitting. They will just appear in the resulting command line literally:
$ echo "What a lovely day; and sunny, too!" What a lovely day; and sunny, too!
Step Input:
read name; echo $name
Step Output:
read name
and
echo $name
Command expansion and evaluation
The remaining steps are processed for each individual command.
Step 4: Parse special operators.
Look through each command to see whether there are any special operators such as {..}, <(..), < ..., <<< .., .. | .., etc. These are all processed in a specific order. If the command is compound, then Redirection operators that apply to that command are evaluated, and the command is processed following rules specific to each compound command, with different expansion steps either suppressed or applied depending on context.
If the command is simple, then both assignment statements preceding commands (unless set -k is enabled) and redirections anywhere within the command are removed and saved for processing after step 5.
Step 5: Perform Expansions.
Bash has many operators that involve expansion. The simplest of these is $parameter. The dollar sign followed by the name of a parameter, which optionally might be surrounded by braces, is called Parameter Expansion. What Bash does here is basically just replace the Parameter Expansion operator with the contents of that parameter. As such, the command echo $USER will in this step be converted to echo lhunath with me. Other expansions include Pathname Expansion (echo *.txt), Command Substitution (rm "$(which nano)"), etc.
Step Input:
echo "$PWD has these files that match *.txt :" *.txt
Step Output:
echo /home/lhunath/docs has these files that match *.txt : bar.txt foo.txt
Step 6: Execute the command.
- Now that the command has been parsed into a command name and a set of arguments, Bash executes the command and sets the command's arguments to the list of words it has generated in the previous step. If the command type is a function or builtin, the command is executed by the same Bash process that just went through all these steps. Otherwise, Bash will first fork off (create a new bash process), initialize the new bash processes with the settings that were parsed out of this command (redirections, arguments, etc.) and execute the command in the forked off bash process (child process). The parent (the Bash that did these steps) waits for the child to complete the command.
Step Input:
sleep 5
Causes:
├┬· 33321 lhunath -bash
│├──· 46931 lhunath sleep 5
- Now that the command has been parsed into a command name and a set of arguments, Bash executes the command and sets the command's arguments to the list of words it has generated in the previous step. If the command type is a function or builtin, the command is executed by the same Bash process that just went through all these steps. Otherwise, Bash will first fork off (create a new bash process), initialize the new bash processes with the settings that were parsed out of this command (redirections, arguments, etc.) and execute the command in the forked off bash process (child process). The parent (the Bash that did these steps) waits for the child to complete the command.
After these steps, the next command, or next line is processed. Once the end of the file is reached (end of the script or the interactive bash session is closed) bash stops and returns the exit code of the last command it has executed.
Graphical Example
For a simplified example of the process, see: http://stuff.lhunath.com/parser.png
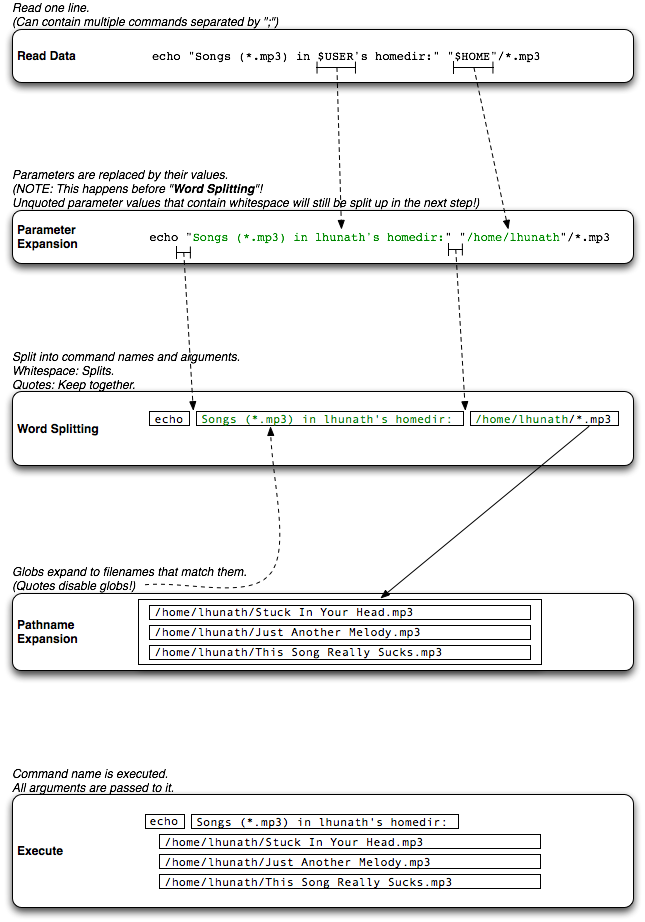{kind=link}
Note that word-splitting (also WordSplitting) or field splitting is used incorrectly in this graphic and confused with argument splitting, which is performed before expansions and is based upon whitespace (except in traditional Bourne shells), rather than the value of IFS during field splitting, which occurs just before pathname expansion.
Common Mistakes
These steps might seem like common sense after looking at them closely, but they can often seem counter-intuitive for certain specific cases. As an example, let me enumerate a few cases where people have often made mistakes against the way they think bash will interpret their command:
start=1; end=5; for number in {$start..$end}: Sequence Expansion happens in step 4, while Parameter Expansion happens in step 5 (this Bash-specific). Brace Expansion tries to expand {$start..$end} but can't. It sees the $start and $end as strings, not Parameter Expansions and gives up:
- Step 4 Results:
start=1 end=5 for number in {$start..$end}Step 5 Results:start=1 end=5 for number in {1..5}And number will now become {1..5} instead of 1. No Brace Expansion has been performed.
- Step 4 Results:
[ $name = B. Foo ]: Word Splitting will break this example. The test program ([) looks for four arguments in this case. A left hand side, an operator, a right hand side, and a closing ]. To find out what's wrong with this command, do as Bash does: Chop the command up into arguments. Assuming name contains B. Foo:
[
B.
Foo
=
B.
Foo
]
A whole lot more than four. You need to use Quotes to prevent the space between B. and Foo from causing Word Splitting. Quote the B. Foo AND the $name so that when $name is expanded, the whitespace in B. Foo is treated the same as on the right hand side. It is important to remember that step 5 (Perform Expansion) comes before step 6 (Split the command into a command name and arguments). That means that $name is not safe from having its result cut up, because the cutting up happens after $name is replaced by the value within name.
Remember that parts of the language that evaluate their input as full bash expressions such as eval, . / source, trap, mapfile, and several other features open up another can of worms. The data given them gets run through the full bash parser and is subject to all evaluation steps. The trouble is that often times before your code even gets to be used by these features, it gets subjected to unavoidable undesired evaluation steps that occur during the act of passing the data. Side-effects that hurt code-integrity are hard to control especially when influenced by user-input. It is also easy to violate good coding principles by mixing code stored in non-code datastructures into code that's to be evaluated.
Languages that have datastructures specifically designed for holding program code (function and object literals, and closures) suffer these problems to a much lesser extent than Bash.